- · 《语言研究》栏目设置[09/30]
- · 《语言研究》数据库收录[09/30]
- · 《语言研究》投稿方式[09/30]
- · 《语言研究》征稿要求[09/30]
- · 《语言研究》刊物宗旨[09/30]
一、稿件要求: 1、稿件内容应该是与某一计算机类具体产品紧密相关的新闻评论、购买体验、性能详析等文章。要求稿件论点中立,论述详实,能够对读者的购买起到指导作用。文章体裁不限,字数不限。 2、稿件建议采用纯文本格式(*.txt)。如果是文本文件,请注明插图位置。插图应清晰可辨,可保存为*.jpg、*.gif格式。如使用word等编辑的文本,建议不要将图片直接嵌在word文件中,而将插图另存,并注明插图位置。 3、如果用电子邮件投稿,最好压缩后发送。 4、请使用中文的标点符号。例如句号为。而不是.。 5、来稿请注明作者署名(真实姓名、笔名)、详细地址、邮编、联系电话、E-mail地址等,以便联系。 6、我们保留对稿件的增删权。 7、我们对有一稿多投、剽窃或抄袭行为者,将保留追究由此引起的法律、经济责任的权利。 二、投稿方式: 1、 请使用电子邮件方式投递稿件。 2、 编译的稿件,请注明出处并附带原文。 3、 请按稿件内容投递到相关编辑信箱 三、稿件著作权: 1、 投稿人保证其向我方所投之作品是其本人或与他人合作创作之成果,或对所投作品拥有合法的著作权,无第三人对其作品提出可成立之权利主张。 2、 投稿人保证向我方所投之稿件,尚未在任何媒体上发表。 3、 投稿人保证其作品不含有违反宪法、法律及损害社会公共利益之内容。 4、 投稿人向我方所投之作品不得同时向第三方投送,即不允许一稿多投。若投稿人有违反该款约定的行为,则我方有权不向投稿人支付报酬。但我方在收到投稿人所投作品10日内未作出采用通知的除外。 5、 投稿人授予我方享有作品专有使用权的方式包括但不限于:通过网络向公众传播、复制、摘编、表演、播放、展览、发行、摄制电影、电视、录像制品、录制录音制品、制作数字化制品、改编、翻译、注释、编辑,以及出版、许可其他媒体、网站及单位转载、摘编、播放、录制、翻译、注释、编辑、改编、摄制。 6、 投稿人委托我方声明,未经我方许可,任何网站、媒体、组织不得转载、摘编其作品。
DeepMind最新研究:如何将「大语言模型」 训练到
作者:网站采编关键词:
摘要:作者丨维克多 Transformer的提出距离我们已经有5年的时间,随着模型规模的不断增长,性能提升也逐渐出现边际效益递减的情况。如何训练出最优性能的大模型? 最近,DeepMind做了一项调

Transformer的提出距离我们已经有5年的时间,随着模型规模的不断增长,性能提升也逐渐出现边际效益递减的情况。如何训练出最优性能的大模型?

最近,DeepMind做了一项调查,想弄清AI语言模型的规模和token之间的关系。这个小组训练了超过400个模型,规模从7000万参数到160亿参数不等,token数量从50亿到5000亿不等。
该小组发现,模型参数大小和token的数量成正相关,换句话说,当模型规模加倍的时候,token也应该加倍。
目前确实是大模型时代,自从1750亿参数的GPT-3横空出世时,勾起了研究员的兴趣。近两年的时间,业界陆续推出了好几个模型,且一个比一个大,并且在多数任务上获得了令人令人深刻的性能。
但这种超越认知的性能表现,是以巨大的计算和能源消耗为代价,业界也一直在讨论这种代价是否值得。例如前谷歌研究员Timnit Gebru就曾撰写论文讨论“AI 语言模型是否太大以及科技公司在降低潜在风险方面做得是否足够。”她也因为该论文被谷歌解雇。
大模型的训练预算一般是提前计划好的,毕竟训练一次成本太大。因此,在给定预算的条件下,准确估计最佳模型超参数变得非常关键。之前,也有学者已经证明参数的数量和自回归语言模型(autoregressive language model)的性能之间存在幂律关系。
 ?
?
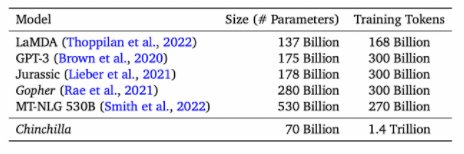
例如先前的研究表明,10倍计算预算对应增加5.5倍模型规模,以及1.8倍的token数量。但这项研究表明:模型大小和token的数量应该成等比例增长。
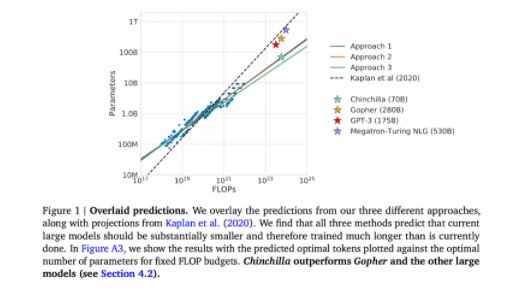
此外,研究员还预测,对于训练Gopher(2800亿个参数的语言模型),最佳模型应该小4倍,并且应该在大4倍的token上进行训练。这一预测,在包含1.4万亿个token的 Chinchilla中的训练得到验证。Chincilla的性能优于Gopher,由于模型规模减小,推理成本也更低。
 ?
?
大模型只有在大数据集上才能发挥最大的效力,同时,DeepMind也注意到,处理大数据集时需要格外小心,训练集和测试集的合理划分,才能最小化语言建模损失以及最优赋能下游任务。
研究界必须考虑与此类大型模型相关的伦理和隐私问题。正如过去所讨论:从网络上收集的大型数据集包含有毒的语言、偏见和私人信息。
关于大模型如何更高效的问题,近日,清华大学刘知远从模型架构层面也提出了看法《清华刘知远:大模型「十问」,寻找新范式下的研究方向》,他表示:
随着大模型越变越大,对计算和存储成本的消耗自然也越来越大。最近有人提出GreenAI的概念,即需要考虑计算能耗的情况来综合设计和训练人工智能模型。面向这个问题,我们认为,随着模型变大,AI会越来越需要跟计算机系统进行结合,从而提出一个更高效面向大模型的支持体系。一方面,我们需要去建设更加高效分布式训练的算法,在这方面国内外都有非常多的相关探索,包括国际上比较有名的DeepSpeed 以及悟道团队在开发的一些加速算法。
另一个方面,大模型一旦训练好去使用时,模型的“大”会让推理过程变得十分缓慢,因此另外一个前沿方向就是如何高效将模型进行尽可能的压缩,在加速推理的同时保持它的效果。这方面的主要技术路线包括剪枝、蒸馏、量化等等。同时最近我们发现,大模型里面具有非常强的稀疏发放的现象,这对于模型的高效压缩和计算有着非常大的帮助,这方面需要一些专门算法的支持。

雷峰网
文章来源:《语言研究》 网址: http://www.yyyjzzs.cn/zonghexinwen/2022/0414/1421.html
上一篇:国际最新研究:完全闭锁患者或有望使用脑机接
下一篇:澳门大学成立语言学研究中心